Asciidoctor for Progress Reports
[ asciidoctor , update ]
Monthly progress reports are a common occurance when managing projects. Some thoughts related to the use of AsciiDoc for progress reports.
Problem Definition
One of our main customers asks us to submit monthly progress reports. This has traditionally been done by writing a Word document. The progress reports contains both static and dynamic content. Static content include some text blocks and headers. Dynamic content include text, progress tables, a list of open actions, and a schedule which should be visualised as a GANTT chart.
So far, progress reports have been done using Word (or for the rebellious, Libre Office). This has naturally entailed a lot of copy pasting of content.
The prose which describes the project status can not be removed at present. However, the action status, progress tables and GANTT info is available in JIRA. Action items have typically been copy-pasted from JIRA into Word. The GANTT chart have been updated by modifying the Microsoft Project file, and then exporting the plots as an image.
The above describes the theory. In reality the tables and charts often do not get properly updated.
The approach thus have three problems: Firstly, the progress reports are inconsistent with project state. Secondly, the updates are error prone, leading to unneccssary errors. Thirdly, the updating wastes a lot of time if done correctly.
Solving the Problem
Clearly a better way to manage these reports have been needed for some time. In our organisation project tasks and risks have typically been mantained in Jira. By taking advantage of the JIRA REST API, we can automate the creation of project status information.
We have used Asciidoctor for some time order to maintain technical documents. This is the first time we attempt to use Asciidoctor for doucments like this.
Initially I wrote some Asciidoctor block processor extensions. The extensions were generating the tables whenver asciidoctor-pdf was run. This approach worked, but was at the same time wrong. The main problem was that we did not keep snapshots of the dynamic data. Documents could thus not be regenerated from source. To solve the issue, we reverted to running scripts that emitted include files. The include files can then be committed in git. Subjecting the whole document to content review via pull requests.
Exporting JIRA Tasks
We use the jira-ruby REST API gem to access our JIRA server.
# gem install jira-ruby
require 'jira-ruby'
require 'yaml'
client = JIRA::Client.new(YAML.load_file("options.yaml"))
project = client.Project.find('MYPROJECT')
File.open("out.adoc", "w") do | f |
f.puts "|==="
f.puts "| ID | Severity"
f.puts ""
project.issues.each do |issue|
if issue.type.name == "Risk"
f.puts "| #{issue.id} | #{issue.severity}"
end
end
f.puts "|==="
endEmitting Tables
We have to emitt a number of tables:
-
Open actions and actions closed during the last month
-
Risk register
Emitting Gantt Charts
In addition to the table, we have to maintain a Gantt chart. Often these have been done using MS Project, however the actual state that developers maintain is often in JIRA or other revision system.
Hence we started generating GANTT charts by using the PlantUML GANTT chart syntax.
# gem install jira-ruby
require 'jira-ruby'
require 'yaml'
client = JIRA::Client.new(YAML.load_file("options.yaml"))
project = client.Project.find('MYPROJECT')
File.open("out.adoc", "w") do | f |
f.puts "[plantuml, svg]"
f.puts "----"
f.puts "@startgantt"
project.issues.each do |issue|
f.puts "[#{issue.name}] lasts #{issue.end - issue.start} days"
end
f.puts "@endgantt"
f.puts "----"
endWhich gives us something like:
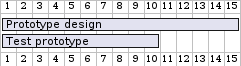
There are some drawbacks with the approach above. Primarily that GANTT charts in plantuml dont scale vertically. Thus for a longer project, when embedding in a PDF, the chart will be unreadable.
This could be solved if the charts could be generated with scales other than days.
Social Aspects
One of the main issues raised about migrating from Word to someting geeky is that non techy persons cannot be bothered with reviewing plain text files.
This is indeed a problem in certain organisations.
We have seen that much of this is that the reviewer expects to be able to comment about style issues that are no longer in manual control.
Although accepting that style and layout comments belong to the template, it was pointed out that it may be difficult to determine which issues belong where.
There is however one rule that is easy to follow. If it is possible to comment on the issue in the plain text format (e.g. AsciiDoc), then it belongs in a source review (e.g. merge or pull request).
If it is related to anything visual like:
-
Fonts
-
Kerning
-
Page breaks
-
Hypenation
Then the comment should be directed as an issue on the template repository.
Future
Not all documents need autogenerated content. However, we get a better, more uniform review process. We also get a guaranteed document style, simplifying document review.
Consequently, we will try to deploy the method on more projects in the future. I have big hopes for the approach taken.